
For the purposes of the international conference Qurator-2021 (Conference on Digital Curation Technologies) the team of DataScouting in collaboration with the School of Philology of the Aristotle University of Thessaloniki and the Department of Informatics and Computer and Telecommunications Engineering of the International University of Greece, proposed a paper with title: “OCR Workflow: Facing Printed Texts of Ancient, Medieval and Modern Greek Literature”.
Qurator is a conference that contributes to the field of Artificial Intelligence, promoting innovative digital communication solutions, aimed at the best possible management of the huge amount of information.
Book digitization is being increasingly enhanced, as it facilitates not only the dissemination and preservation of cultural heritage but also the analysis of large amounts of textual data as well as the extraction and discovery of knowledge in a faster, dynamic and interactive way. Quite often, OCR, as the core technology of book digitization, has to address major difficulties related to the condition of the primary source or to scanning issues. The main contribution of this paper is to provide an extensive study on Tesseract, an open-source OCR system, including image pre-processing and text post-processing methods, that overcome a variety of image handling problems. Additionally, a re-trained Greek language model, based on individual fonts training plus pairs of image-text training, is being provided. Finally, this paper proposes a pipeline of methods, including text line detection, that result in enhanced accuracy for Greek Literature documents, even when they consist of distorted pages, due to scanning issues or damaged physical material.
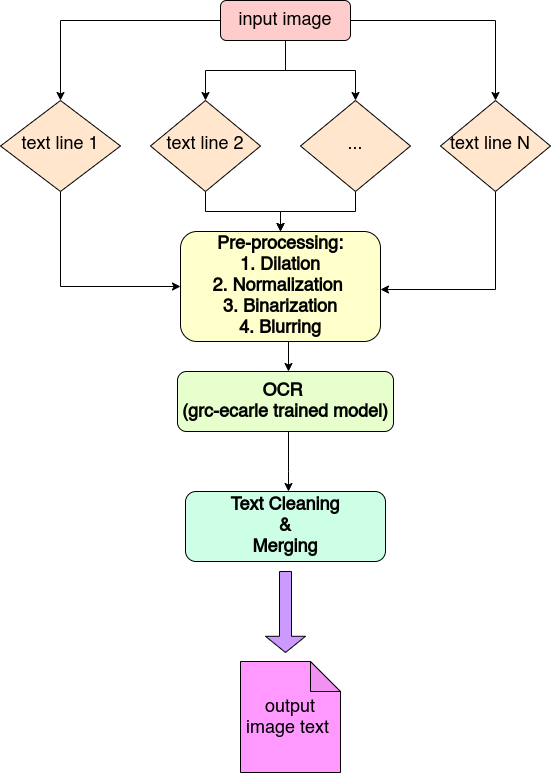
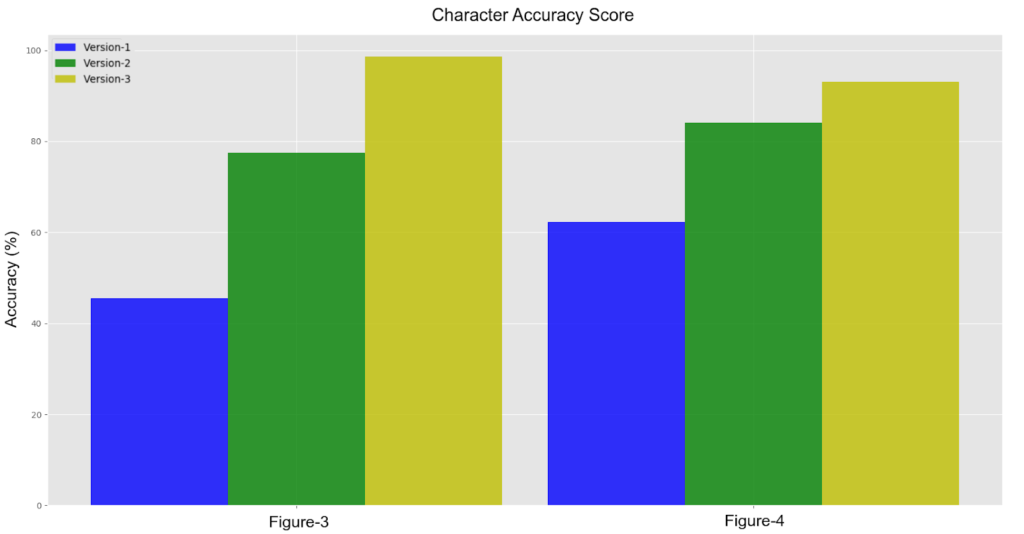
Bar-chart of the accuracy of OCRed text for each version in two random pages