
Semantic indexing as an information extraction problem, aims to assign semantic concepts to documents in natural language. In literature, this is an important process since it enables the works of literature to be searched and retrieved by such concepts.
Our new paper “Semantic Indexing of 19th-Century Greek Literature Using 21st-Century Linguistic Resources”, which was recently published in the special issue on “Cultural Heritage Storytelling, Engagement and Management in the Era of Big Data and the Semantic Web” of the MDPI Sustainability journal, documents the problem in Greek literature of 19th century and suggests the use of the current language model named BERT in combination with the TextRank algorithm for building a representative set of sentences/phrases from documents aiming to solve the problem. Using transfer learning, the model can be trained on recent works of literature from 21st century written in modern Greek language and index works written in katharevousa from 19th century. The representative set of sentences/phrases improves the performance of the language model and indicates a solution for building semantic indexing models considering a part of the documents rather than the entire text.
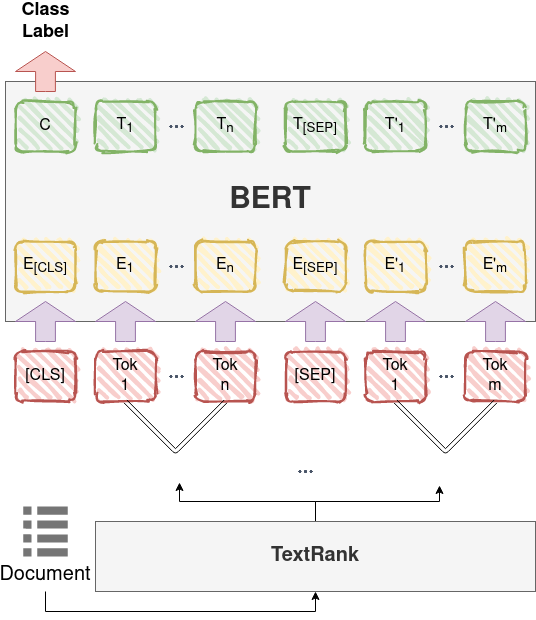
Figure 1 illustrates the semantic indexing process for a work of literature. Firstly, the document passes as input to the TextRank algorithm, and a set of sentences/phrases are extracted. Next, the TextRank outcome passes to the BERT model which is responsible for automated semantic indexing of the document.
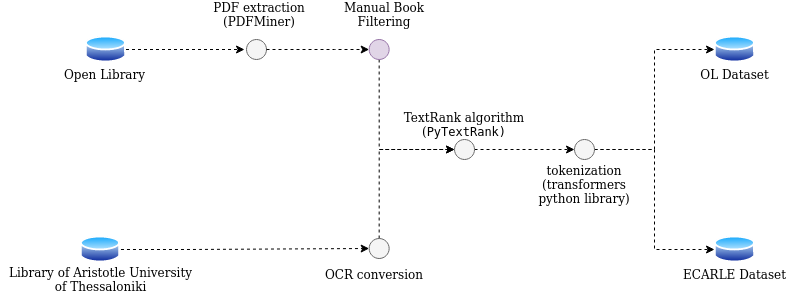
Figure 2: Retrieval and preprocessing of works of literature
Our paper also gives emphasis to the linguistic resources that were used for training the BERT using works of literature from 21st century and for the validation process on works of literature from 19th century. Figure 2 shows the process of retrieving the works of literature and their preprocessing.