
Relation Extraction (RE) aims to detect semantic relations between entity pairs in natural texts. Although it has proven to be crucial in various natural language processing (NLP) applications, it has not yet been studied in depth in the literature. Among the key challenges is that literary texts put emphasis on the narrative craft and exhibit characteristics that go beyond the well-studied structured form of journalistic, academic, and technical texts. Moreover, literary texts are characterized by creative writing peculiarities that can vary significantly from author to author and time to time. Moreover, since most literary works have been digitized by OCR systems, the digitized versions may suffer from character or word misspellings. Despite the aforementioned challenges, the digitization of texts and advances in Artificial Intelligence (AI) and NLP are enabling the automatic analysis of literary works, allowing us to delve into the structure of artifacts and to compare, explore, manage, and preserve the richness of our written heritage.
Our work, «Extracting Semantic Relationships in Greek Literary Texts» which was recently published in the special issue «Cultural Heritage Storytelling, Engagement and Management in the Era of Big Data and the Semantic Web», explores the task of relation extraction in light of above mentioned challenges in 19th century Greek literature. Precisely, we propose the fine-tuning of the Greek language model BERT into a structured input of 19th century Greek literary instances containing only the surrounding text of the entity pair along with their entity types. Moreover, we use multi-instance learning, i.e., we train our model not on the instance level, but on a set of instances including the same entity pairs.
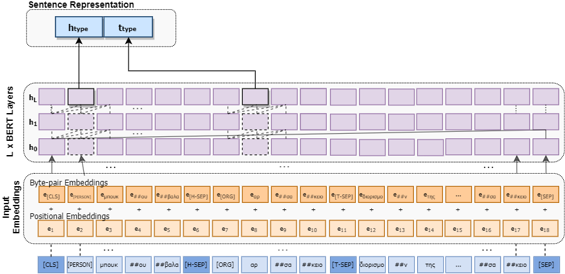
Using transfer learning, well-structured input, and multi-instance learning, our model effectively handles literature’s challenges. Extensive experiments and comparisons with existing models on our dataset show that REDSandT_Lit has superior performance (90% accuracy), manages to capture infrequent relations (100%F in long-tail relations), and can also correct mislabeled sentences.
Finally, we have made the training data publicly available. These include 3,649 samples of 19th century Greek literary instances labelled with five (5) named entities and six (6) semantic relations to encourage further research in Greek literature.