
Η Εξαγωγή Σχέσεων, ως πρόβλημα εξαγωγή πληροφορίας, στοχεύει στην εξαγωγή σημασιολογικών σχέσεων μεταξύ ζεύγων οντοτήτων σε κάποιο φυσικό κείμενο. Αν και έχει αποδειχθεί ζωτικής σημασίας σε ποικίλες εφαρμογές της φυσικής επεξεργασίας γλώσσας (NLP) δεν έχει μελετηθεί εκτενώς κάτω από το πρίσμα της λογοτεχνίας. Οι λόγοι είναι αφενός γιατί τα λογοτεχνικά κείμενα σε σχέση με τα δημοσιογραφικά ή ακαδημαϊκά δίνουν μεγαλύτερη έμφαση στην αφήγηση ακολουθώντας πιο χαλαρές δομές και αφετέρου διότι ο δημιουργικός λόγος μπορεί να διαφέρει σημαντικά ανά συγγραφέα και κατά καιρούς. Επιπλέον, καθώς τα περισσότερα έργα έχουν ψηφιοποιηθεί μέσω συστημάτων αυτόματης αναγνώρισης χαρακτήρων (OCR), οι ψηφιοποιημένες εκδόσεις μπορεί να υποφέρουν από ορθογραφικά λάθη σε επίπεδο χαρακτήρων ή λέξεων. Παρά των παραπάνω προκλήσεων, η ψηφιοποίηση των κειμένων και οι σύγχρονες έρευνες στον τομέα της τεχνητής νοημοσύνης (ΑΙ) & του NLP επέτρεψαν την αυτόματη ανάλυση και λογοτεχνικών πλέον έργων δίνοντας μας τη δυνατότητα να εξερευνήσουμε, να διαχειριστούμε και να διατηρήσουμε τον πλούτο της γραπτής πολιτισμικής μας κληρονομιάς.
Στην εργασία μας, «Εξαγωγή σημασιολογικών σχέσεων σε ελληνικά λογοτεχνικά κείμενα» που δημοσιεύτηκε πρόσφατα στο ειδικό τεύχος με θέμα «Αφήγηση, ενασχόληση με και διαχείριση πολιτιστικής κληρονομιάς στην εποχή των μεγάλων δεδομένων και του σημασιολογικού ιστού» εξερευνούμε το πρόβλημα την εξαγωγής σχέσεων κάτω από το πρίσμα των παραπάνω προκλήσεων στην ελληνική λογοτεχνία του 19ου αι. Συγκεκριμένα, προτείνουμε την αναπροσαρμογή του νεοελληνικού γλωσσικού μοντέλου BERT σε μια δομημένη είσοδο ελληνικών λογοτεχνικών προτάσεων του 19ου αι. που συμπεριλαμβάνει το περιβάλλον κείμενο του ζεύγους οντοτήτων και τους ονοματικούς τύπους αυτών. Επιπλέον, εκπαιδεύουμε το μοντέλο όχι σε επίπεδο προτάσεων, αλλά σε σύνολα προτάσεων (multi-instance learning) που χαρακτηρίζονται από τα ίδια ζεύγη οντοτήτων.
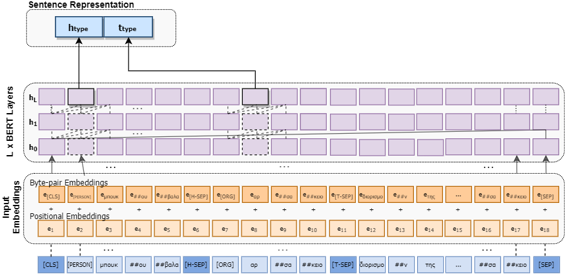
Μέσω της μεταφοράς μάθησης από την νεοελληνική γλώσσα, τη δομημένη είσοδο και την εκπαίδευση με multi-instance learning, το μοντέλο μας κατορθώνει να διαχειριστεί αποτελεσματικά τις προκλήσεις της λογοτεχνίας. Εκτεταμένα πειράματα και συγκρίσεις με υπάρχοντα μοντέλα φανερώνουν την υπεροχή του μοντέλου μας, REDSandT_Lit, το οποίο έχει γενική ακρίβεια 90%, ενώ καταφέρνει να συλλάβει σπάνιες σχέσεις με 100% ακρίβεια και να διορθώσει λαθεμένα επισημασμένες προτάσεις.
Τέλος, διαθέτουμε τα δεδομένα εκπαίδευσης. Αυτά περιλαμβάνουν 3,649 δείγματα από ελληνικά λογοτεχνικά τεκμήρια του 19ου αι. επισημασμένα με πέντε (5) ονοματικές οντότητες και έξι (6) σχέσεις, ώστε να ενθαρρύνουμε την έρευνα στην ελληνική λογοτεχνία.