
Η Εξαγωγή Σχέσεων στοχεύει στην εξαγωγή σημασιολογικών σχέσεων μεταξύ ζεύγων οντοτήτων σε κάποιο φυσικό κείμενο, ενώ έχει αποδειχθεί ζωτικής σημασίας σε ποικίλες εφαρμογές της φυσικής επεξεργασίας γλώσσας (NLP), όπως τα συστήματα ερωτοαπαντήσεων και η ενίσχυση γνωσιακών βάσεων.
Αν και τα συστήματα εποπτευόμενης μάθησης αποτελούν τη τυπική οδό για την εξαγωγή σχέσεων, η απαίτησή τους σε μεγάλο όγκο δεδομένων που σπάνια είναι διαθέσιμο, έχει επικεντρώσει τις πρόσφατες έρευνες σε μεθόδους απομακρυσμένης εποπτείας (DS). Αυτές μπορούν να δημιουργήσουν αυτόματα ένα μεγάλο αριθμό δεδομένων εκπαίδευσης ευθυγραμμίζοντας σχεσιακές εγγραφές από κάποια γνωσιακή βάση σε ελεύθερο κείμενο που περιλαμβάνει αυτές τις σχέσεις. Ωστόσο, οι μέθοδοι αυτοί πλήττονται από λαθεμένες ετικέτες, ενώ οι υπάρχουσες έρευνες αδυνατούν να αναγνωρίσουν τις πιο σπάνιες σχέσεις.
H εργασία μας “Improving Distantly-Supervised Relation Extraction Through BERT-Based Label and Instance Embeddings” έχει ως στόχο ένα καινοτόμο σύστημα απομακρυσμένης εποπτείας που καταφέρνει να μειώσει αποτελεσματικά το θόρυβο από τις λαθεμένες ετικέτες και να αναγνωρίσει ένα ευρύτερο σύνολο σχέσεων. Αυτό επιτυγχάνεται, με την εστίαση του μοντέλου μας, REDSandT (Relation Extraction with Distant Supervision and Transformers), στα πιο σχετικά τμήματα που αφορούν την υπο-εξερεύνηση σχέση μέσω της αναπροσαρμογής του BERT σε μια δομημένη είσοδο που συμπεριλαμβάνει το μέρος της πρότασης που συνδέει ένα ζεύγος οντοτήτων και τους ονοματικούς τύπους αυτών. Χρησιμοποιώντας τα εξαγόμενα διανύσματα του ζεύγος οντοτήτων παράγουμε διανυσματικές αναπαραστάσεις για τις υποβόσκουσες σχέσεις, τις οποίες χρησιμοποιούμε ως μηχανισμό προσοχής στις προτάσεις για να μειώσουμε περαιτέρω το θόρυβο. Η τελική αναπαράσταση των προτάσεων προκύπτει από την συνένωση των διανυσμάτων της πρότασης και της υποβόσκουσας σχέσης, με πειράματα στα δύο Αγγλικά σύνολα δεδομένων αναφοράς να παρουσιάζουν αποτελέσματα στην αιχμή της τεχνολογίας. H παρακάτω εικόνα παρουσίαζει την αναπαράσταση των προτάσεων στο μοντέλο μας. Ο κώδικας, τα εκπαιδευμένα μοντέλα και τα δεδομένα μας είναι δημόσια διαθέσιμα.
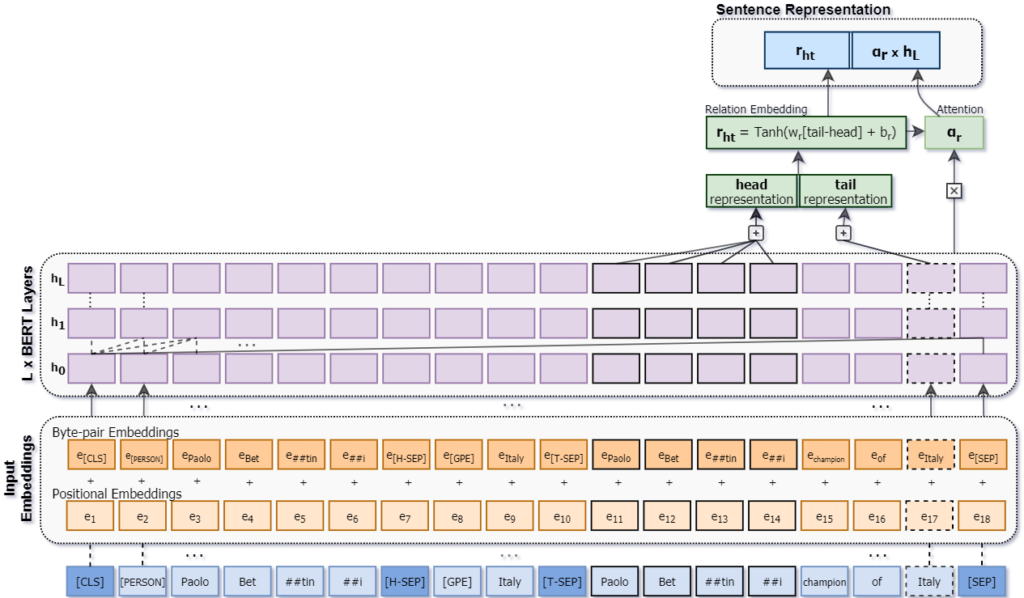
Η αναπαράσταση των προτάσεων στο μοντέλο REDSandT
Στο μέλλον στόχο έχουμε να επεκτείνουμε αυτή τη δουλειά για το έργο του ΕCARLE και συγκεκριμένα για να εξάγουμε σχέσεις από ελληνικά σύνολα δεδομένων που εμφανίζουν τους ίδιους περιορισμούς που αντιμετωπίζονται σε αυτή τη δουλειά: το ελληνικό σύνολο δεδομένων του έργου έχει κατασκευαστεί μέσω απομακρυσμένης εποπτείας ευθυγραμμίζοντας σχεσιακές εγγραφές με ελληνικά κείμενα, ενώ η κατανομή των σχέσεων είναι άνιση.