
Στο πλαίσιο του διεθνούς συνεδρίου Qurator-2021 (Conference on Digital Curation Technologies) η ομάδα της DataScouting σε συνεργασία με το τμήμα Φιλολογίας του Αριστοτελείου Πανεπιστημίου Θεσσαλονίκης και με το τμήμα Μηχανικών Πληροφορικής, Υπολογιστών και Τηλεπικοινωνιών του Διεθνούς Πανεπιστημίου της Ελλάδας, πρότεινε για δημοσίευση το άρθρο με τίτλο “OCR Workflow: Facing Printed Texts of Ancient, Medieval and Modern Greek Literature”.
Το Qurator είναι ένα συνέδριο που για αρκετά χρόνια συνεισφέρει στον τομέα της Τεχνητής Νοημοσύνης, προβάλλοντας καινοτόμες λύσεις ψηφιακής επικοινωνίας, που αποσκοπούν στην καλύτερη δυνατή διαχείριση του τεράστιου όγκου πληροφορίας, τον οποίο καλούνται να διαχειριστούν οι διάφοροι οργανισμοί.
Το άρθρο αρχικά θίγει το θέμα της ψηφιοποίησης των τεκμηρίων, που καθιστά εφικτή τόσο την συντήρηση όσο και την διάδοση της πολιτιστικής μας κληρονομιάς. Συγκεκριμένα, τονίζεται η ανάγκη για άμεση και ποιοτική εξαγωγή πληροφορίας από έναν τεράστιο όγκο κειμενικών δεδομένων, μέσω της τεχνολογίας Οπτικής Αναγνώρισης Χαρακτήρων (Optical Character Recognition – OCR).
Αρκετά συχνά η ποιότητα του OCR κειμένου, υφίσταται σημαντική υποβάθμιση εξαιτίας των διαφόρων προβλημάτων (βλ. ατέλειες στην πρώτη ύλη ή κατά το σκανάρισμα) που εντοπίζονται στις ψηφιοποιημένες σελίδες των τεκμηρίων. Η βασική συνεισφορά του άρθρου εναπόκειται στην πραγματοποίηση μιας εμπεριστατωμένης έρευνας γύρω από το σύστημα OCR του Tesseract, που αναμφισβήτητα αποτελεί ένα εργαλείο με τεχνολογία αιχμής. Επιπρόσθετα, το άρθρο πραγματεύεται την υλοποίηση τεχνικών ανάλυσης εικόνας και κειμένου, που επιτυγχάνουν περαιτέρω ενίσχυση της ακρίβειας του OCR ενώ παρουσιάζει ένα επαν-εκπαιδευμένο ελληνικό μοντέλο, που εστιάζει στην εκπαίδευση σε μια μοναδική γραμματοσειρά καθώς και σε ζεύγη εικόνας-κειμένου. Τέλος, το άρθρο προτείνει ένα πρωτότυπο σύστημα διεργασιών, συμπεριλαμβανομένου του text line detection, που όπως αποδεικνύεται -ύστερα από αξιολόγηση σε πολυσέλιδα τεκμήρια της Ελληνική Λογοτεχνίας- οδηγεί σε αναβαθμισμένη ποιότητα OCR κειμένου, ακόμα και στις περιπτώσεις που οι σελίδες έχουν υποστεί σημαντική φθορά.

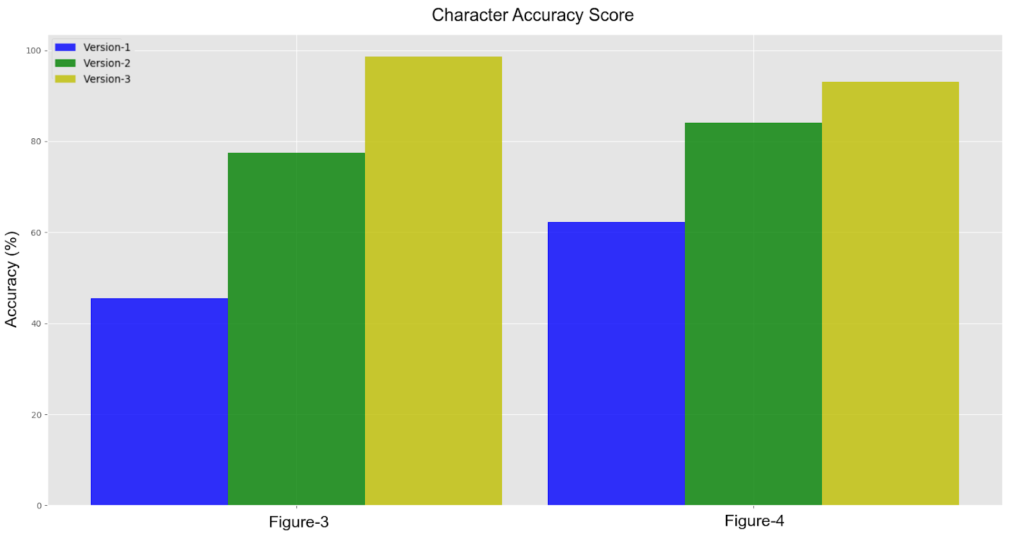
Παράδειγμα εκτέλεσης OCR σε τυχαία σελίδα. *Version-1: Tesseract default greek model. **Version-2: Re-trained greek model on a single font (grc-ecarle). ***Version-3: Proposed method (pipeline and grc-ecarle). 
Bar-chart της ακρίβειας του OCRed text για κάθε Version σε δύο τυχαίες σελίδες.
Τo pipeline της προτεινόμενης μεθόδου.